博客
MrDoc + Ollama:用一张3060搭建低成本纯内网 AI 知识库
为什么 LLM Wiki 那么火,MrDoc 还是选择了 RAG
使用 MrDoc 构建人机友好的 AI 知识库
本站点使用「觅思文档专业版」构建
-
+
首页
MrDoc + Ollama:用一张3060搭建低成本纯内网 AI 知识库
最近几个月一直在开发和完善 MrDoc 的内置AI知识库功能,一开始其实只是为了添加一个轻量(之前的Dify方案太重了)且贴合MrDoc权限系统的内置AI问答入口。 但越做越发现,对于很多内网用户来说,AI 知识库的价值似乎比想象中大得多。 因为对于内网用户来说,他们的很多内部资料天然就不适合上传公网,知识库本地部署,本来就是唯一选择。 甚至有些团队的网络环境直接就是纯内网隔离环境,机器压根就不能访问外网。 这种情况下,云端 AI、大模型 SaaS、在线AI知识库,就算功能好用到爆炸,也从来不在考虑范围,本地 AI 知识库成了唯一的选择。 那本地AI知识库,势必就要涉及到AI大模型的本地部署。 一说到AI大模型本地部署,很多人下意识里就会想到 AI 服务器、机房、多卡GPU,但是对于MrDoc的很多用户来说,此路明显不通嘛。 毕竟MrDoc本身就是一个非常具有经济性(便宜)、偏轻量化的知识库系统。 很多团队选择 MrDoc,本来就是图个可私有化部署并且成本低、好维护,对硬件要求不高。结果为了搞个本地 AI 知识库,反手再上几十万 AI 服务器。这个预算别说财务了,可能部门领导看完都得先看看你最近精神状态正不正常。你看他批预算还是批你。 正好我的本地开发电脑上就有一张之前为了跑 AI 生图配的 12G 显存 RTX 3060 显卡,索性拿它测试 MrDoc + 本地模型,能不能在普通办公电脑上,稳定地运行一个数据不出内网还能正常问答的 AI 知识库。 ## 选择什么模型 AI知识库主要需要使用到三种模型: - 文本向量化 - 切片重排 - 文本回答生成 MrDoc已经内置了一个简单的重排算法,所以重排模型也可以不用。 文本向量化模型选择了主流的`bge-m3`。 难点在于LLM文本生成模型的选择,毕竟我的显卡只有12G显存。 首先让AI给出了一个显存和LLM模型适配表: | GPU显存 | FP16 大致能力 | 4bit量化 大致能力 | 适合模型 | | ----- | --------- | ----------- | -------- | | 4GB | 1B~3B | 7B | 轻量聊天、小工具 | | 6GB | 3B~7B | 7B~14B | 日常对话 | | 8GB | 7B | 14B | 主流入门部署 | | 10GB | 7B~14B | 14B~20B | 编程/办公 | | 12GB | 14B | 20B~32B | 较强推理 | | 16GB | 14B~20B | 32B | 很实用的甜点位 | | 24GB | 32B | 70B(低速) | 高质量推理 | | 32GB | 32B~70B | 70B | 企业/重度玩家 | | 48GB | 70B | 100B级 | 多并发 | | 80GB | 70B FP16 | 100B+ | 数据中心级 | 根据这个表,我的显卡显然只能跑14B以下的LLM模型。而在12G显存之下,要让LLM大模型完全加载,还留有问答对话的上下文空间,LLM大模型的显存占用显然不能超过10G,极限也就是9B的模型。 9B的模型看起来参数量小,但是和知识库问答场景还是很适配的。和其他的大模型应用场景(比如程序员最喜欢拿代码生成来判断一个模型好不好用)不一样,知识库问答更侧重于文档理解和组织,更加看重稳定性和服从性,也就是正确理解给出的上下文,然后按照Prompt的要求组织语言输出回答,不胡编瞎说。 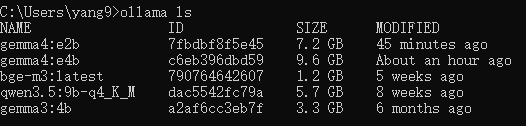 这一类小参数模型里面就不要想DeepSeek之类的模型,Qwen和Gemma算是最好的选择。 这边选择的是`qwen3.5:9b` ## 怎么运行模型 如上图所示,这边使用ollama来部署和运行大模型。 本地部署 AI 模型的方法其实还有很多,比如llama.cpp、vLLM、Xinference、LocalAI。 但对于很多企业内网环境而言,“简单稳定”,比“极限性能”更重要。 而 Ollama 最大的优势,就是安装门槛非常低,使用起来非常简单。 拉取模型和运行模型也直接一条命令就可以搞定: ``` ollama pull 模型名称 ``` ``` ollama run 模型名称 ``` ollama也提供了兼容OpenAI风格的接口,也就是`http://127.0.0.1:11434/v1`,访问`http://127.0.0.1:11434/v1/models`你还可以看到当前可用的模型: 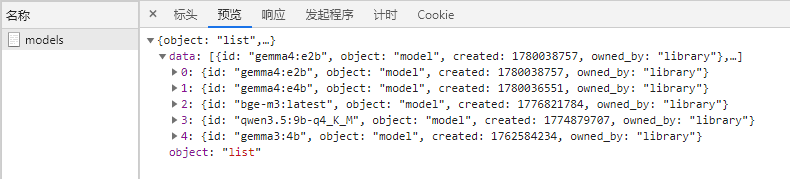 ## 结果比预想中的要好 原本只是抱着试试看的心态在3060 12G显存上跑AI大模型,具体的效果并不抱太大的希望。但是实际的效果却比预想中的要好。 先来看回答的效果。 在导入一个《MrDoc使用手册》的文集并对文集文档进行切片之后,向AI助手问一个我被问了无数次的问题:“如何在文档里面显示附件”: 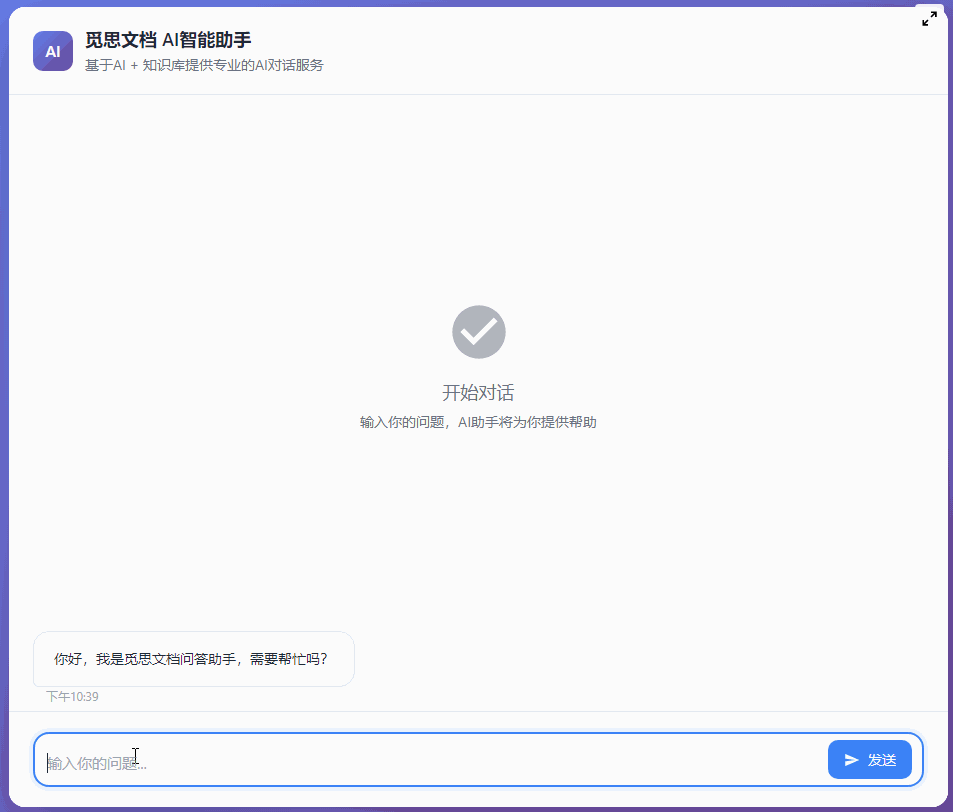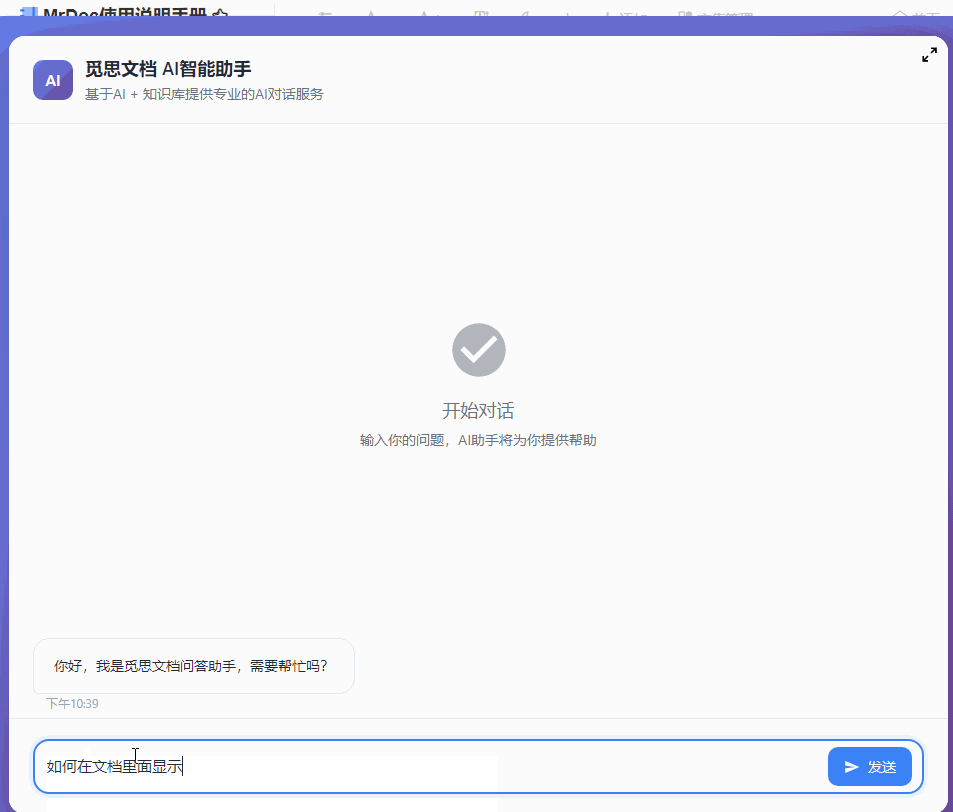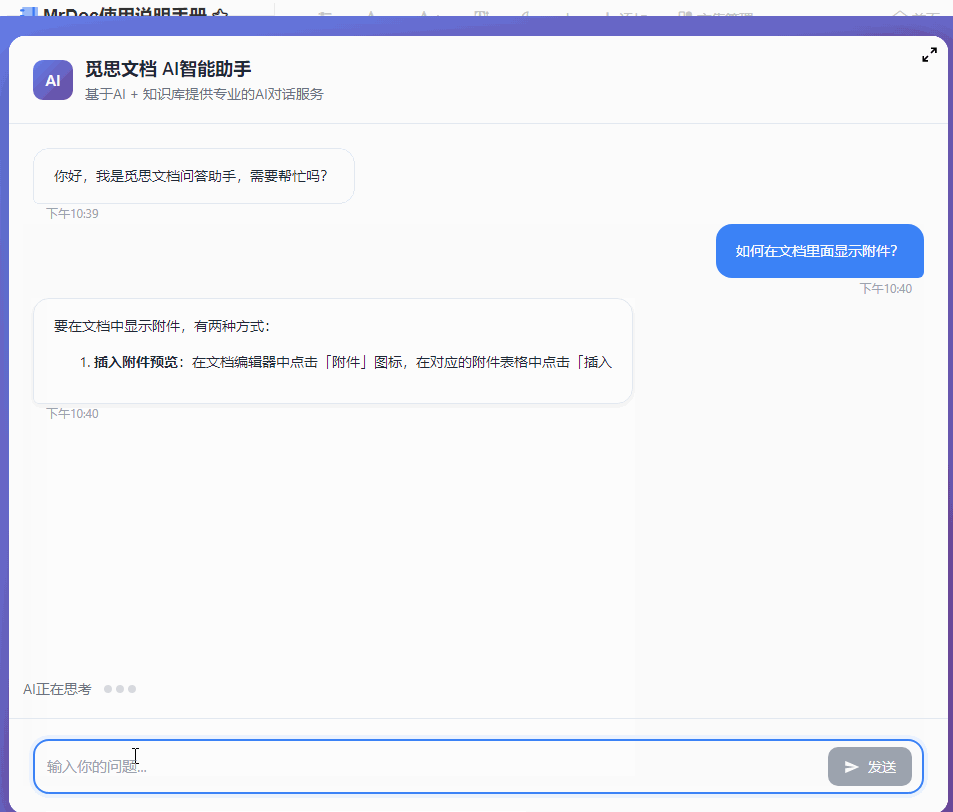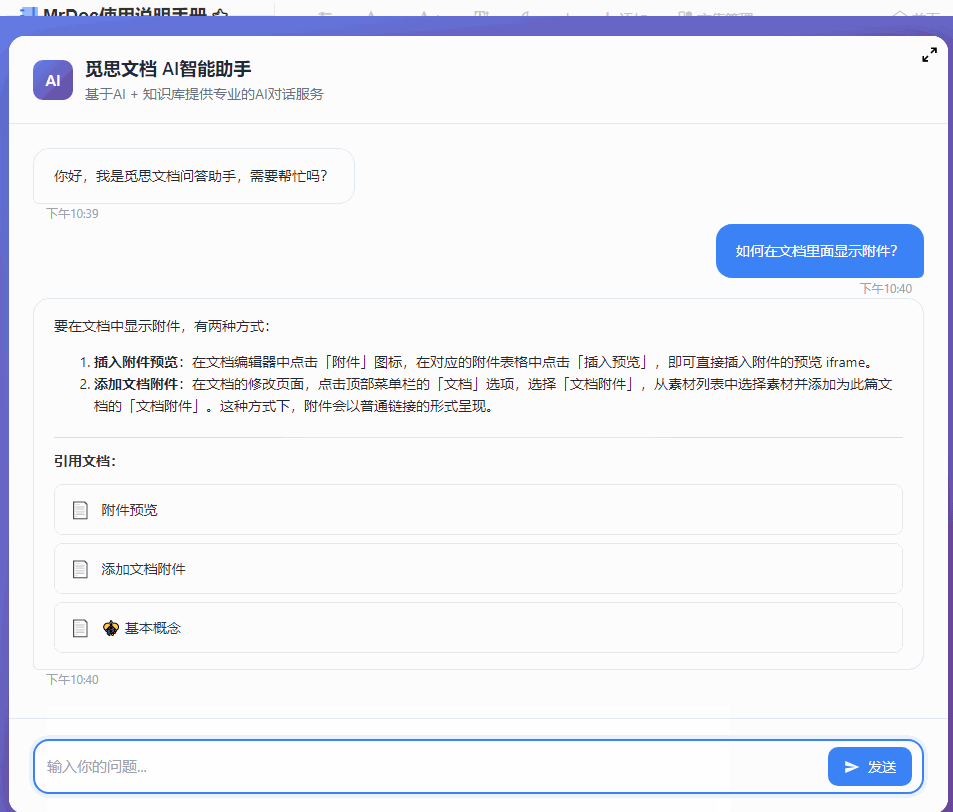 再来一个经常被问到的问题:“如何在文集里面新建文件夹”: 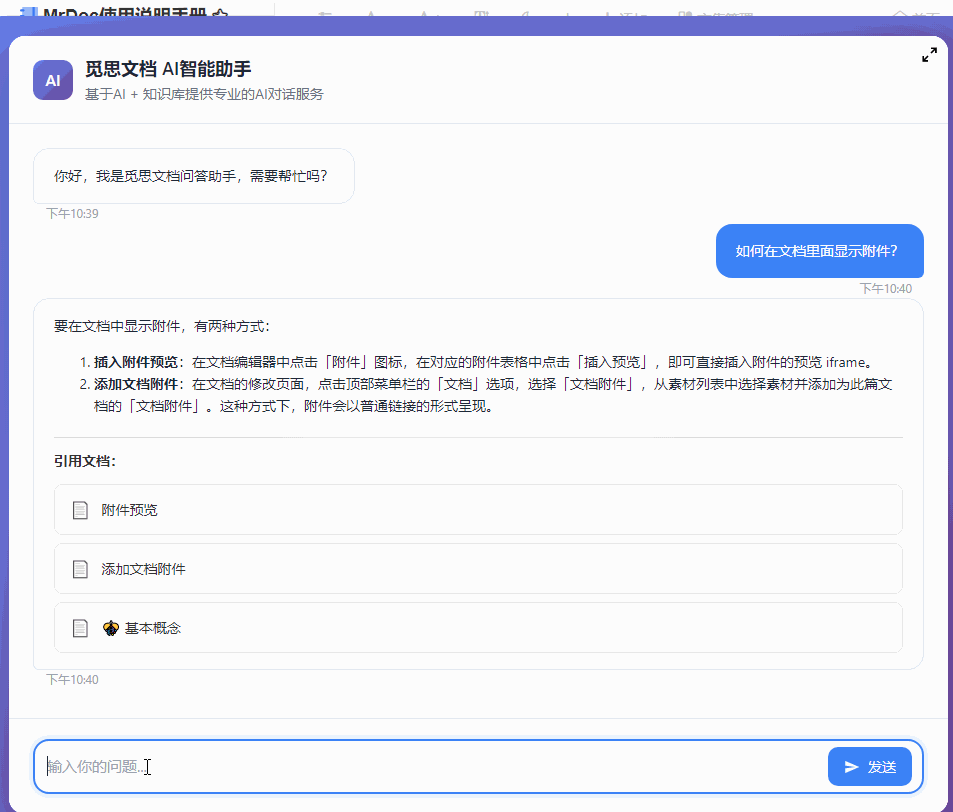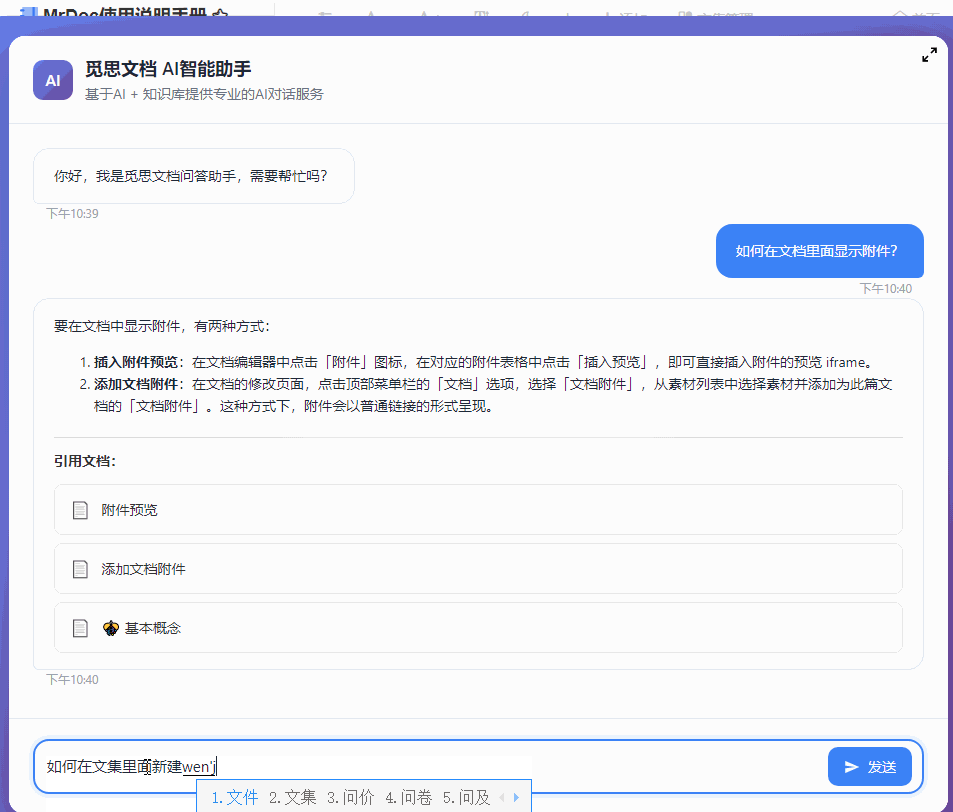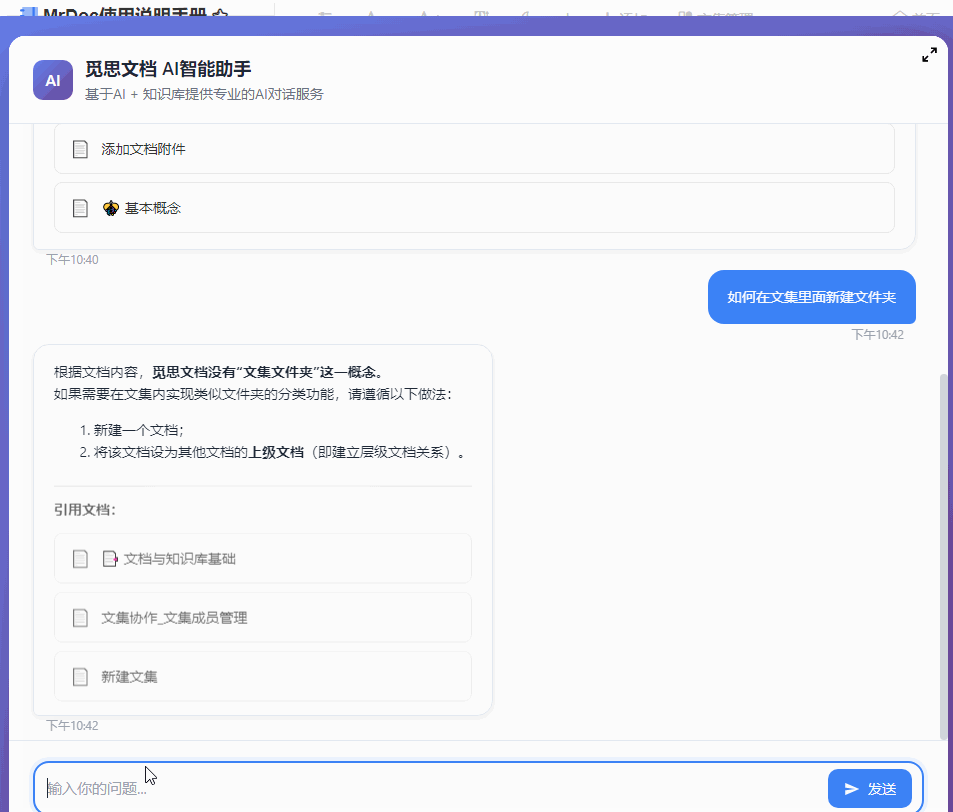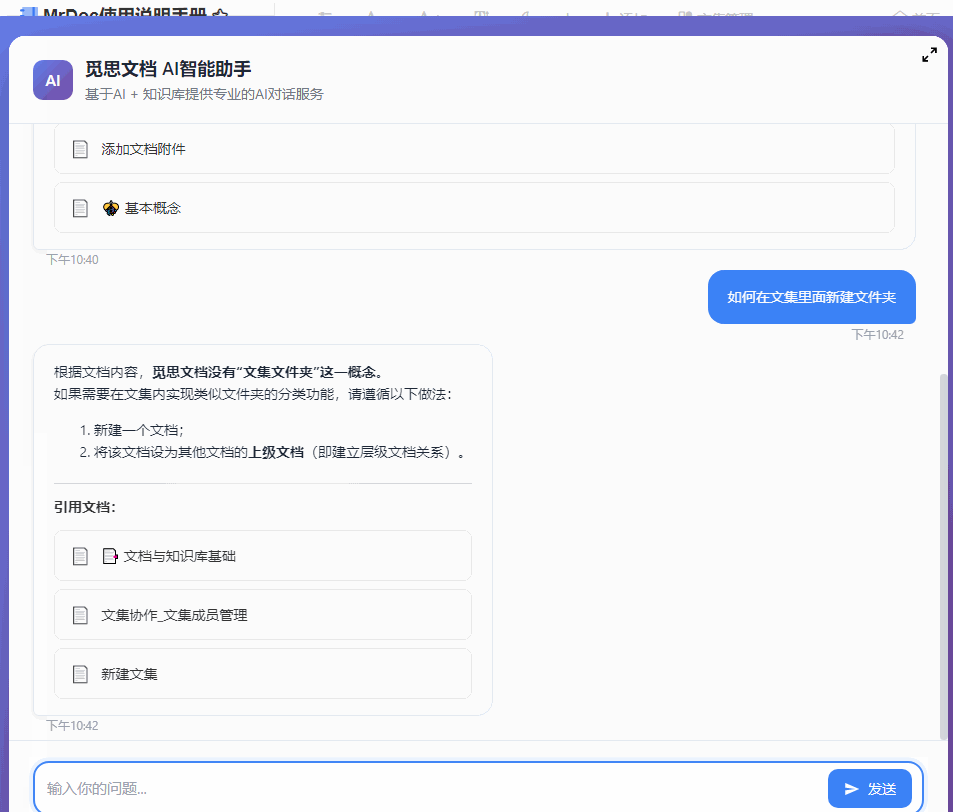 回答得都很完美。 ## 整个流程是怎么跑起来的 整个方案其实并不复杂,用的也都是传统AI知识库问答的RAG方案。本地部署MrDoc和Ollama之后,让MrDoc去调用 Ollama 的接口。 整体链路大概是: ``` 用户提问 ↓ MrDoc 检索知识库 ↓ 向量召回相关内容 ↓ 拼接参考上下文 ↓ Ollama 调用本地模型生成答案 ``` 整个过程都可以不经过公网,把网线拔了照样能跑。 这对内网用户来说很关键,因为他们的环境里面,不能联网,本身就是硬性要求。 ## MrDoc 是什么角色 看到用的是传统RAG方案,有些人会想,那我直接用Ollama + chatbox之类的AI聊天工具不也一样可以进行知识库问答?用 MrDoc 简直是多此一举。 其实,对于团队的AI知识库来说,真正麻烦的部分反而不是文档向量化处理和大模型的调用,很多时候文档管理那一整套功能(文档管理、权限体系)才是决定AI知识库能否用下去的关键。 因为个人用AI时文档完全可以乱丢乱传、一股脑丢给大模型,团队的知识库则必须是结构化、权限化的,否则时间一长,整个知识库肯定越来越混乱。 而这些东西,恰恰才是 MrDoc 一直在做的事情。普通用户在平时依然可以建文集、写文档、上传Office/PDF、设置访问权限和查看转发文档。AI更像是在传统知识库基础上的增强能力。 所以,MrDoc 在这里的角色更偏向于“知识中台”,人负责写文档、看文档、管理文档,AI则负责查文档、理解文档、组织回答和链接文档。 这里其实也是 MrDoc 和很多“纯 AI 产品”不太一样的地方。 这一类的 AI 知识库产品,无论是SaaS化的平台,还是私有部署的产品,要想使用起来,用户得专门导入本地文件、更新文档内容,而 MrDoc 本身就是一个完整的文档系统。 所以在MrDoc这里的流程和操作都很自然。 用户新建和更新文档时,后台自动完成文档解析、文本切片、embedding 向量化、存入向量数据库等等一系列设计AI知识库的操作,用户不需要额外操作。 按照传统方式使用知识库时,走的还是`文集 → 文档 → 阅读`的模式;如果进入 AI 问答,系统则会触发RAG 检索这一套流程。 ## 真正的价值 其实很多团队需要的,并不是什么参数巨大的模型,也不是什么功能花哨的 AI 平台。 受限于成本和专业能力,他们既不关心,也未必看得懂。他们需要的只是一个能够读取内部文档、理解内部知识、能够回答日常问题,并且数据还不出内网的智能问答助手。 但是在过去,本地 AI几乎与 AI 服务器、多卡 GPU和几十万预算等概念等价,仿佛不花点大钱,就跟AI无缘。 不过这边实际测试下来发现,对于知识库问答这种场景来说,所需要的硬件门槛其实很低很低。 我自己的一台普通开发电脑(i5-12400 + RTX 3060 12G)配合MrDoc + Ollama(bge-m3 + qwen3.5:9b-q4_K_M),就已经能够搭建起一个完整的内网 AI 知识库。 在2026年的今天,小参数量的模型已经可以媲美过去一些大参数量的模型了,知识库问答自然也不在话下,至少从我这次测试来看,RTX 3060 12G 并没有成为瓶颈。 对于很多内网环境来说,这样的配置未必强大,但却可能是性价比最高的方案。 在如此普通的配置下,把文档管理、知识检索和 AI 问答串成一个完整闭环,这个方案的价值就很高。 低成本的配置对老板来说剩下了大笔开支,不俗的表现也可以让员工愿意持续使用。 对于不少中小企业、工厂、学校或者各类内网环境来说,这样的方案或许没有那么“高大上”,但真正部署起来的时候,反而更接近现实。 从此 AI 知识库也就不再是大企业和高预算团队的专属,毕竟一台普通电脑,也能成为企业自己的知识助手。
州的先生
2026年5月30日 11:00
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
分享
链接
类型
密码
更新密码
有效期
Markdown文件
Word文件
PDF文档
PDF文档(打印)